Gap Sentences Generation in PEGASUS
Selection strategies of self-supervised learning for pre-training
Dec 14, 2021 by Yan Ding
1. Recap self-supervised learning
In the BERT paper, they used the masked language model and next-sentence prediction to do pre-training because Corpus like Wikipedia or BooksCorpus are unlabeled documents. In that paper, they called it “unsupervised learning”. But later it is referred to as “self-supervised learning”. Although both mean training a neural network without labeled data. But “unsupervised learning” mainly refers to reinforcement learning. So it is proper to distinguish them. Here comes the term “self-supervised learning” because it can learn by itself with masking 10% or 15% words or sentences and predict these masked words.

2. GSG in PEGASUS
Gap sentences generation(GSG) is introduced in the PEGASUS paper. They were inspired by Masked LM in BERT and proposed this method of self-supervised learning for pre-training. Simply speaking, GSG is selecting several sentences from documents and concatenating them into a pseudo-summary. Then using these pseudo-summary as labels for training the model. This is used in the pre-training stage.
How to select these sentences? There are three strategies for selecting m gap sentences.
2.1 Random
Uniformly selecting m sentences at random to be its pseudo-summary.

2.2 Lead
Select the first m sentences as a pseudo-summary of the document. Below is a document with selected sentences in red.

2.3 Principal
Select top-m scored sentences according to importance. As a proxy for importance, computing ROUGE1- F1 between the sentence and the rest of the document.
si = rouge(xi , D \ {xi}), ∀i
In this formulation sentences are scored independently (Ind) and the top m selected. This is called Ind-Orig. Below is the same document and the pseudo-summary is selected in blue according to principal gap sentence selection, more precisely is Ind-Orig.

3. Effect of selecting strategies for pre-training
What about the effects of these three selecting strategies to the training result? In the PEGASUS paper, researchers are also compared which one is the best. Below are six variants of GSG (Lead, Random, Ind-Orig, Ind-Uniq, Seq-Orig, Seq-Uniq) while choosing 30% sentences as gap sentences.
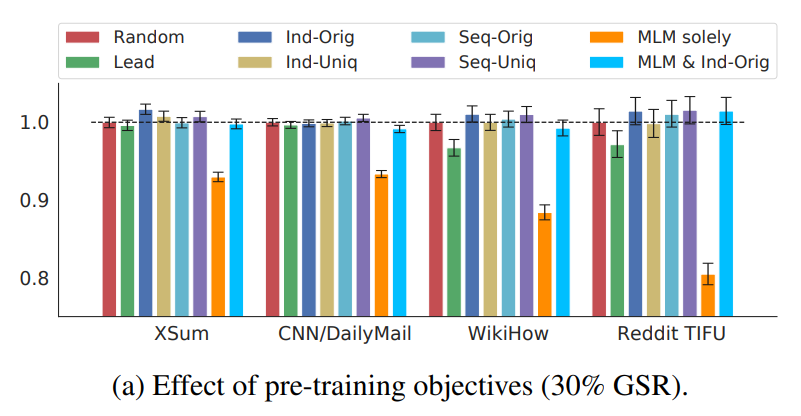
As you can see in the above figure, Ind-Orig achieved the best performance across these 4 downstream datasets: XSum, CNN/DailyMail, WikiHow and Reddit TIFU. Moreover, Ind-Orig has relatively stable performance in four datasets. While Lead has better effect in XSum and CNN/DailyMail dataset but worse in WikiHow and Reddit. We can take a look at those datasets from Google dataset. For the first two datasets, the topic is usually in the lead of docs because they are news-like docs. But for WikiHow and Reddit, they are quite different. Usually the topic is not in the lead. So if picking the lead as the pseudo-summary, the effect will not be good. That also explains why Ind-Orig, which is one of the principle selection strategies, can have the best effect because it can extract the main idea or topics from input documents. On the other hand, pseudo-summary as pseudo-labels selected in this way has much higher accuracy. So it carries out better results in the pre-training stage as well as doing good for downstream tasks.
4. Summary
In this article, we discussed three selection strategies of Gap Sentence Generation for pre-training and their effects in downstream tasks. Ind-Orig, which is one of the principle selection strategies, has best performances compared with other 5 variants of GSG. I hope this article can help you better understand the pre-training procedure of PEGASUS. If you have any questions, please leave comments below. Thank you for reading!
